1. mapValues
mapValues算子 ,作用于 [K,V] 格式的RDD上,并且只对V(Value)进行操作,Key值保持不变。
(1)将[K,V] 格式的List转换为[K,V] 格式的RDD。
scala> val rdd = sc.makeRDD(List(("Tom",100),("Mike",80)))
rdd: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[2] at makeRDD at :24
(2)使用mapValues算子,将value值乘以100,key值保持不变
scala> val rdd2=rdd.mapValues(_*100)
rdd2: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[1] at mapValues at :26
(3)使用collect算子回收,查看结果
scala> rdd2.collect
res0: Array[(String, Int)] = Array((Tom,10000), (Mike,8000))
2. mapPartitions
作用于RDD上的每一个分区,传递的函数相当于一个迭代器,有几个分区,就会迭代几次。
object Test1 {
def main(args: Array[String]): Unit = {
val conf=new SparkConf()
.setMaster("local[*]")
.setAppName(this.getClass.getSimpleName)
val sc=new SparkContext(conf)
val rdd=sc.makeRDD(List(1,2,3,4,5,6),3);
val values: RDD[Int] = rdd.mapPartitions(t => {
t.map(_ * 10)
})
//打印输出结果
values.foreach(println)
}
}
使用上面的代码进行测试。输出结果如下:

可以看到,因为设置了3个分区,所以相应启动了3个任务,在每个分区上进行迭代计算。
3. filter
filter算子过滤出所有的满足条件的元素。
另外fliter算子不会改变分区的数量,所以经过过滤后,即使某些分区没有数据了,但是分区依然存在的。
scala> val rdd1 = sc.makeRDD(List(1,2,3,4,5,6),3)
rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[2] at makeRDD at :24
scala> val rdd2 = rdd1.filter(_>3)
rdd2: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[3] at filter at :26
scala> rdd2.partitions.size
res3: Int = 3
4. sortBy
sortBy算子按照指定条件进行排序。
我们使用下面的代码进行测试:
object Test2 {
def main(args: Array[String]): Unit = {
val conf=new SparkConf()
.setMaster("local[*]")
.setAppName(this.getClass.getSimpleName)
val sc=new SparkContext(conf)
val rdd: RDD[(String, Int)] = sc.makeRDD(List(("Tom", 80), ("Mike", 90), ("Mary", 85),("John",60)))
//按value值升序排列
val res1: RDD[(String, Int)] = rdd.sortBy(_._2)
res1.collect.foreach(println)
// 按value值降序排列
val res2: RDD[(String, Int)] = rdd.sortBy(_._2, false)
res2.collect.foreach(println)
}
}
升序输出的结果如下:

降序输出的结果如下:
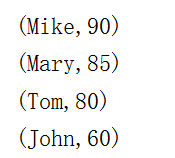
有一点需要说明的是,输出结果前,要使用collect算子把结果回收到本地。因为数据是分散在集群各节点的,如果不回收,看到的结果可能是不正确的。
>>本文地址:https://www.ujiuye.com/zhuanye/2021/69463.html
声明:本站稿件版权均属中公教育优就业所有,未经许可不得擅自转载。






1 您的年龄
2 您的学历
3 您更想做哪个方向的工作?
 大前端
大前端 大数据
大数据 互联网营销
互联网营销 Java
Java Linux
Linux Python
Python 嵌入式
嵌入式 全域电商运营
全域电商运营 软件测试
软件测试 室内设计
室内设计 平面设计
平面设计 电商设计
电商设计 网页设计
网页设计 UI设计
UI设计 VR/AR
VR/AR 网络安全
网络安全 新媒体
新媒体 直播带货
直播带货 智能机器人
智能机器人Copyright©1999-
北京中公教育科技有限公司 .All Rights Reserved
京ICP备10218183号-88
京ICP证161188号
 京公网安备11010802020723号
京公网安备11010802020723号
 投诉建议:400-650-7353
投诉建议:400-650-7353

 Java培训
Java培训
 软件测试培训
软件测试培训
 Web培训
Web培训
 Linux培训
Linux培训
 Python培训
Python培训
 互联网营销培训
互联网营销培训
 UI培训
UI培训
 大数据培训
大数据培训 官方公众号 回复"大礼包"享福利
官方公众号 回复"大礼包"享福利  领学习资料 分享IT知识
领学习资料 分享IT知识 







